Named Distributions as Artifacts
On confusing priors with models
Being Abraham de Moivre and being born in the 17th century must have been a really sad state of affairs. For one, you have the bubonic plague thing going on, but even worse for de Moivre, you don't have computers and sensors for automated data collection.
As someone interested in complex-real world processes in the 17th century, you must collect all of your observations manually, or waste your tiny fortune on paying unreliable workers to collect it for you. This is made even more complicated by the whole "dangerous to go outside because of the bubonic plague" thing.
As some interested in chance and randomness in the 17th century, you've got very few models of "random" to go by. Sampling a uniform random variable is done by literally rolling dice or tossing a coin. Dice which are imperfectly crafted, as to not be quite uniform. A die (or coin) which limits the possibilities of your random variable between 2 and 20 (most likely 12, but I'm not discounting the existence of medieval d20s). You can order custom dice, you can roll multiple dice and combine the results into a number (e.g. 4d10 are enough to sample uniformly from between 1 and 10,000), but it becomes increasingly tedious to generate larger numbers.
Even more horribly, once you tediously gather all this data, your analysis of it is limited to pen and paper, you are limited to 2 plotting dimensions, maybe 3 if you are a particularly good artist. Every time you want to visualize 100 samples a different way you have to carefully draw a coordinate system and tediously draw 100 points. Every time you want to check if an equation fits your 100 samples, you must calculate the equation 100 times... and then you must compute the difference between the equation results and your samples, and then manually use those to compute your error function.
I invite you to pick two random dice and throw them until you have a vague experimental proof that the CLT holds, and then think about the fact that this must have been de Moivrea's day to day life studying proto-probability.
So it's by no accident, misfortune, or ill-thinking that de Moivre came up with the normal distribution [trademarked by Gauss] and the central limit theorem (CLT).
A primitive precursor of the CLT is the idea that when two or more independent random variables are uniform on the same interval, their sum will be defined by a normal distribution (aka Gaussian distribution, bell curve).
This is really nice because a normal distribution is a relatively simple function of two variables (mean and variance), it gives de Moivre a very malleable mathematical abstraction.
However, de Moivre's definition of the CLT was that, when independent random variables (which needn't be uniform) are normalized to the same interval and then summed, this sum will tend towards the normal distribution. That is to say, some given normal distribution will be able to fit their sum fairly well.
The obvious issue in this definition is the "tend towards" and the "random" and the "more than two". There's some relation between these, in that, the fewer ways there are for something to be "random" and the more of these variables one has, the "closer" the sum will be to a normal distribution.
This can be formalized to further narrow down the types of random variables from which one can sample in order for the CLT to hold. Once the nature of the random generators is known, the number of random variables and samples needed to get within a certain error range of the closest possible normal distribution can also be approximated fairly well.
But that is beside the point, the purpose of the CLT is not to wax lyrically about idealized random processes, it's to be able to study the real world.
De Moivre's father, a proud patriot surgeon, wants to prove the sparkling wines of Champagne have a fortifying effects upon the liver. However, doing autopsies is hard, because people don't like having their family corpses "desecrated" and because there's a plague. Still, the good surgeon gets a sampling of livers from normal Frenchmen and from Champagne drinking Frenchmen and measures their weight.
Now, normally, he could sum up these weights and compare the difference, or look at the smallest and largest weight from each set to figure out the difference between the extremes.
But the samples are very small, and might not be fully representative. Maybe, by chance, the heaviest Champagne drinker liver he was is 2.5kg, but the heaviest possible Champagne drinker liver is 4kg. Maybe the Champagne drinker livers are overall heavier, but there's one extremely heavy in the control group.
Well, armed with the Normal Distribution and the CLT we say:
Liver weight is probably a function of various underlying processes and we can assume they are fairly random. Since we can think of them as summing up to yield the liver's weight, we can assume these weights will fall onto a normal distribution.
Thus, we can take a few observations about the weights:
Normal Frenchmen: 1.5, 1.7, 2.8, 1.6, 1.8, 1.2, 1.1, 1, 2, 1.3, 1.8, 1.5, 1.3, 0.9, 1, 1.1, 0.9, 1.2
Champagne drinking Frenchmen: 1.7, 2.5, 2.5, 1.2, 2.4, 1.9, 2.2, 1.7
And we can compute the mean and the standard deviation and then we can plot the normal distribution of liver weight (champagne drinkers in orange, normal in blue):
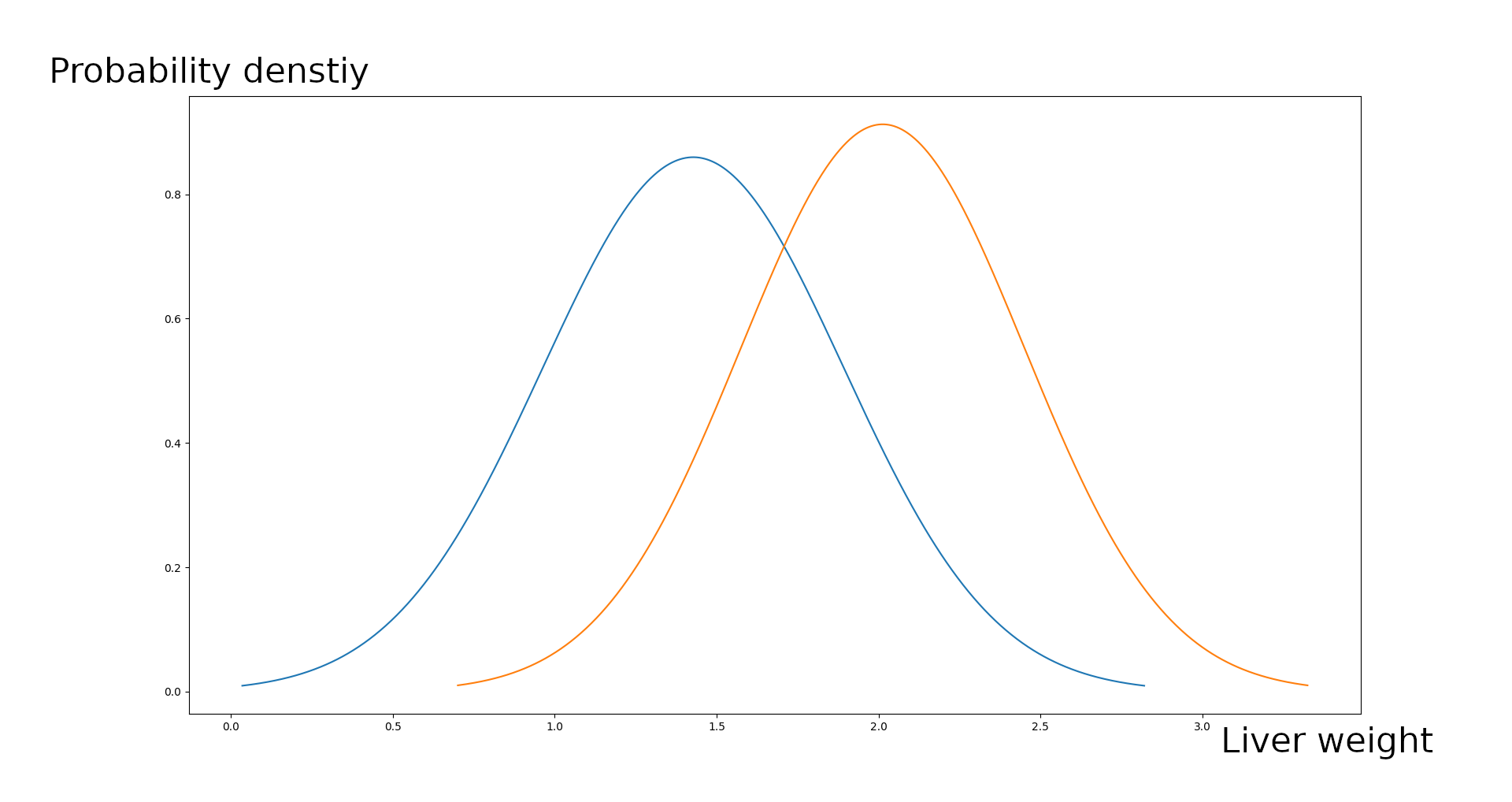
So, what's the maximum weight of a Champagne drinker's liver? 3.3kg
Normal liver? 2.8
Minimum weight? 0.7kg champagne, 0.05kg normal (maybe confounded by babies that are unable to drink Champagne, investigate further)
But we can also answer question like:
For normal people, say, 9/10 people, the ones that aren't at the extreme, what's the range of champagne drinking vs normal liver weights?
Or questions like:
Given liver weight x, how certain are we this person drank Champagne?
Maybe questions like:
Given that I suspect my kid has a tiny liver, say 0.7kg, will drinking Champagne give him a 4/5 chance of fortifying it to 1.1kg?
So the CLT seems amazing, at least it seems amazing until you take a look at the real world, where:
a) We can't determine the interval for which most processes will yield values. You can study the stock market from 2010 to 2019, see that the DOW daily change is between -3% and +4% and fairly random, assume the DOW price change is generated by a random function with values between -3% and 4%... and then March 2020 rolls around and suddenly that function yields -22% and you're ****.
b) Most processes don't "accumulate" but rather contribute in weird ways to yield their result. Growth rate of strawberries is f(lumens, water) but if you assume you can approximate f as lumens*a + water*b you'll get some really weird situation where your strawberries die in a very damp cellar or wither away in a desert.
c) Most processes in the real world, especially processes that contribute to the same outcome, are interconnected. Ever wonder why nutritionists are seldom able to make any consistent or impactful claims about an ideal diet? Well, maybe it'll make more sense if you look at this diagram of metabolic pathway. In the real world, most processes that lead to a shared outcome are so interconnected it's a herculean task to even rescue the possibility of thinking causally.
On a surface level, my intuitions tell me it's wrong to make such assumptions, the epistemically correct way to think about making inferences from data ought to go along the lines of:
You can use the data at your disposal, no more
If you want more data you can either collect more or find a causal mechanism, use it to extrapolate, prove that it's true even at edge cases by making truthful predictions and use that
OR
- If you want more data, you can extrapolate given that you know of a very similar dataset to back up your extrapolation. E.g. if we know the distribution of Englishmen liver sizes, we can assume the distribution of Frenchmen liver sizes might fit that shape. But this extrapolation is just a better-than-random hypothesis, to be scrutinized further based on the predictions stemming from it.
Granted, your mileage may vary depending on your area of study. But no matter how laxly you interpret the above, there's a huge leap to be made from those rules to assuming the CLT holds on real-world processes.
But, again, this is the 17th century, there are no computers, no fancy data collection apparatus, there's a plague going on and to be fair, loads of things, from the height of people to grape yield of a vine, seem to fit the normal distribution quite well.
De Moivre didn't have even a minute fraction of the options we have now, all things considered, he was rather ingenious.
But lest we forget, the normal distribution came about as a tool to:
- Reduce computation time, in a world where people could only use pen and paper and their own mind.
- Make up for lack of data, in a world where "data" meant what one could see around him plus a few dozens of books with some tables attached to them.
- Allow techniques that operate on functions, to be applied to samples (by abstracting them as a normal distribution). In other words, allow for continuous math to be applied to a discrete world.
Artifacts that became idols
So, the CLT yields a type of distribution that we intuit is good for modeling a certain type of process and has a bunch of useful mathematical properties (in a pre-computer world).
We can take this idea, either by tweaking the CLT or by throwing it away entirely and starting from scratch, to create a bunch of similarly useful distribution.... a really really large bunch.
For the purpose of this article I'll refer to these as "Named Distributions". They are distributions invented by various students of mathematics and science throughout history, to tackle some problem they were confronting, which proved to be useful enough that they got adopted into the repertoire of commonly used tools.
All of these distributions are selected based on two criteria:
a) Their mathematical properties, things that allow statisticians to more easily manipulate them, both in terms of complexity-of-thinking required to formulate the manipulations and in terms of computation time. Again, remember, these distributions came about in the age of pen and paper ... and maybe some analog computers which were very expensive and slow to use).
b) Their ability to model processes or characteristics of processes in the real world.
Based on these two criteria we get distributions like Student's t, the chi-square, the f distribution, Bernoulli distribution, and so on.
However, when you split the criteria like so, it's fairly easy to see the inherent problem of using Named Distributions, they are a confounded product between:
a) Mathematical models selected for their ease of use b) Priors about the underlying reality those mathematics are applied to
So, take something like Pythagora's theorem about a square triangle:
h^2 = l1^2 + l2^2.
But, assume we are working with imperfect real-world objects, our "triangles" are never ideal. A statistician might look at 100 triangular shapes with a square angle and say "huh, they seem to vary by at most this much from an ideal 90-degree angle)", based on that, he could come up with a formula like:
h^2 = l1^ + l2^2 +/- 0.05*max(l1^2,l2^2)
And this might indeed be a useful formula, at least if the observations of the statistician generalize to all right angle that appeared in the real world, but a THEOREM or a RULE it is not, not so under any mathematical system from Euclid to Russell.
If the hypotenuse of real-world square triangle proves to be usually within the bound predicted by this formula, and the formula gives us a margin of error that doesn't inconvenience further calculations we might plug it into, then it may well be useful.
But it doesn't change the fact that to make a statement about a "kind of square" triangle, we need to measure 3 of its parameters correctly, the formula is not a substitute for reality, it's just a simplification of reality when we have imperfect data.
Nor should we lose the original theorem in favor of this one, because the original is actually making a true statement about a shared mathematical world, even if it's more limited in its applicability.
We should remember that 0.05*max(l1^2,l2^2) is an artifact stemming from the statistician's original measurements, it shouldn't become a holy number, never to change for any reason.
If we agree this applied version of the Pythagoras theorem is indeed useful, then we should frequently measure the right angle in the real world, and figure out if the "magic error" has to be changed to something else.
When we teach people the formula we should draw attention to the difference: "The left-hand side is Pyathagor's formula, the right-hand side is this artifact which is kind of useful, but there's no property of our mathematics that exactly define what a slightly-off right-angled triangle is or tells us it should fit this rule".
The problem with Named Distributions is that one can't really point out the difference between mathematical truths and the priors within them. You can take the F distribution and say "This exists because it's easy to plug it into a bunch of calculation AND because it provides some useful priors for how real-world processes usually behaves".
You can't really ask the question "How would the equation defining the F-distribution change, provided that those priors about the real world would change". To be more precise, we can ask the question, but the result would be fairly complicated and the resulting F'-distribution might hold none of the useful mathematical properties of the F-distribution.
Are Named Distributions harmful?
Hopefully I've managed to get across the intuition for why I don't really like Named Distributions, they are very bad at separating between model and prior.
But... on the other hand, ANY mathematical model we use to abstract the world will have a built-in prior.
Want to use a regression? Well, that assumes the phenomenon fits a straight line.
Want to use a 2,000,000 billion parameter neural network? Well, that assumes the phenomenon fits a 2,000,000 parameter equation using some combination of the finite set of operations provided by the network (e.g. +, -, >, ==, max, min,avg).
From that perspective, the priors of any given Named Distributions are no different than the priors of any particular neural network or decision tree or SVM.
However, they come to be harmful because people make assumptions about their priors being somewhat correct, whilst assuming the priors of other statistical models are somewhat inferior.
Say, for example, I randomly define a distribution G and this distribution happens to be amazing at modeling people's IQs. I take 10 homogenous groups of people and I give them IQ tests, I then fit G on 50% of the results for each group and then I see if this correctly models the other 50%... it works.
I go further, I validate G using k-fold cross-validation and it gets tremendous results no matter what folds I end up testing it on. Point is, I run a series of tests that, to the best of our current understanding of event modeling, shows that G is better at modeling IQ than the normal distribution.
Well, one would assume I could then go ahead and inform the neurology/psychology/economics/sociology community:
Hey, guys, good news, you know how you've been using the normal distribution for models of IQ all this time... well, I got this new distribution
Gthat works much better for this specific data type. Here is the data I validated it on, we should run some more tests and, if they turn up positive, start using it instead of the normal distribution.
In semi-idealized reality, this might well result in a coordination problem. That is to say, even assuming I was talking with mathematically apt people that understood the normal distribution not to be magic, they might say:
Look, your
Gis indeed x% better than the normal distribution at modeling IQ, but I don't really think x% is enough to actually affect any calculations, and it would mean scrapping or re-writing a lot of old papers, wasting our colleagues time to spread this information, trying to explain this thing to journalists that at least kind of understand what a bell curve is ...etc.
In actual reality, I'm afraid the answer I'd get is something like:
What? This can't be true, you are lying and or misunderstanding statics. All my textbooks say that the standard distribution models IQ and is what should be used for that, there's even a thing called the Central limit theorem proving it, it's right there in the name "T-H-E-O-R-E-M" that means it's true.
Maybe the actual reaction lies somewhere between my two versions of the real world, it's hard to tell. If I were a sociologist I'd suspect there'd be some standard set of reactions μ and they vary by some standard reaction variation coefficient σ, and 68.2% of reactions are within the μ +/-σ range, 95.4% are within the μ +/- 2σ range, 99.6% are within the μ +/-3σ range and the rest are no relevant for publishing in journals which would benefit my tenure application so they don't exist. Then I would go ahead and find some way to define μ and σ such that this would hold true.
Alas, I'm not a sociologist, so I have only empty empirical speculation about this hypothetical.
Other than a possibly misguided assumption about the correctness of their built-in priors, is there anything else that might be harmful when using Named Distributions?
I think they can also be dangerous because of their simplicity, that is, the lack of parameters that can be tuned when fitting them.
Some people seem to think it's inherently bad to use complex models instead of simple ones when avoidable, I can't help but think that the people saying this are the same as those that say you shouldn't quote wikipedia. I haven't seen any real arguments for this point that don't straw-man complex models or the people using them. So I'm going to disregard it for now; if anyone knows of a good article/paper/book arguing for why simple models are inherently better, please tell me and I'll link to it here.
Edit: After reading it diagonally, it seems like this + this provides a potentially good (from my perspective) defense of the idea that model complexity is inherently bad, even assuming you fit properly (i.e. you don't fit directly onto the whole dataset). Leaving this here for now, will give more detail when(if) I get the time to look at it more.
On the other hand, simple models can often lead to a poor fit for the data, ultimately this will lead to shabby evaluations of the underlying process (e.g. if you are evaluating a resulting, poorly fit PDF, rather than the data itself). Even worst, it'll lead to making predictions using the poorly fit model and missing out on free information that your data has but your model is ignoring.
Even worst, simple models might cause discarding of valid results. All our significance tests are based on very simplistic PDFs, simply because their integrals had to be solved and computed in each point by hand, thus complex models were impossible to use. Does this lead discarding data that doesn't fit a simplistic PDF? Since the standard significant tests might give weird results, due to no fault of the underlying process, but rather because the generated data is unusual. To be honest, I don't know, I want to say that the answer might be "yes" or at least "No, but that's simply because one can massage the phrasing of the problem in such a way as to stop this from happening"
I've previously discussed the topic of treating neural networks as a mathematical abstraction for approximating any function. So they, or some other universal function estimators, could be used to generate distributions that perfectly fit the data they are supposed to model.
If the data is best modeled by a normal distribution, the function estimator will generate something that behaves like a normal distribution. If we lack data but have some good priors, we can build those priors into the structure and the loss of our function estimator.
Thus, relying on these kinds of complex models seems like a net positive.
That's not to say you should start with a 1,000M parameter network and go from there, but rather, you should start iteratively from the simplest possible model and keep adding parameters until you get a satisfactory fit.
But that's mainly for ease of training, easy replicability and efficiency, I don't think there's any particularly strong argument that a 1,000M parameter model, if trained properly, will be in any way worst than a 2 parameter model, assuming similar performance on the training & testing data.
I've written a bit more about this in If Van der Waals was a neural network, so I won't be repeating that whole viewpoint here.
In conclusion
I have a speculative impression that statistical thinking is hampered by worshiping various named distribution and building mathematical edifices around them.
I'm at least half-sure that some of those edifices actually help in situations where we lack the computing power to solve the problems they model.
I'm also fairly convinced that, if you just scrapped the idea of using Named Distributions as a basis for modeling the world, you'd just get rid of most statistical theory altogether.
I'm fairly convinced that distribution-focused thinking pigeonholes our models of the world and stops us from looking at interesting data and asking relevant questions.
But I'm unsure those data and questions would be any more enlightening than whatever we are doing now.
I think my complete position here is as follows:
Named Distributions can be dangerous due to people being unaware of the strong epistemic priors embed in them.
It doesn't seem like using Named Distributions to fit a certain process is worse compared to using any other arbitrary model with equal accuracy on the validation data.
However most Named Distributions are very simplistic models and probably can't accurately fit most real-world data (or derivative information from that data) very well. We have models that can account for more complexity, without any clear disadvantages, so it's unclear to me why we wouldn't use those.
Named Distributions are useful because they include certain useful priors about the underlying reality, however, they lack a way to adjust those priors, which seems like a bad enough thing to override this positive.
Named Distributions might pigeonhole us into certain patterns of thinking and bias us towards giving more importance to the data they can fit. It's unclear to me how this affects us, my default assumption would be that it's negative, as with most other arbitrary constraints that you can't escape.
Named Distributions allow for the usage of certain mathematical abstractions with ease, but it's unclear to me whether or not this simplification of computations is needed under any circumstance. For example, it takes a few milliseconds to compute the p-value for any point on any arbitrary PDF using python, so we don't really need to have p-value tables for specific significance tests and their associated null hypothesis distributions.
Epilogue
The clock tower strikes 12, moonlight bursts into a room, finding Abraham de Moivre sitting at his desk. He's computing the mean and standard deviation for the heights of the 7 members of his household, wondering if this can be used as the basis for the normal distribution of all human height.
The ongoing thunderstorm constitutes an ominous enough scenario, that, when lightning strikes, a man in an aluminum retro suit from a 70s space-pop music video appears.
Stop whatever you are doing ! says the time traveler. ...
- Look, this Gaussian distribution stuff you're doing, it seems great, but it's going to lead many sciences astray in the future.
- Gaussian?
- Look, it doesn't matter. The thing is that a lot of areas of modern science have put a few distributions, including your standard distribution, on a bit of a pedestal. Researchers in medicine, psychology, sociology, and even some areas of chemistry and physics must assume that one out of a small set of distributions can model the PDF of anything, or their papers don't will never get published.
... Not sure I'm following.
- I know you have good reason to use this distribution now, but in the future, we'll have computers that can do calculations and gather data billions of times faster than a human, so all of this abstraction, by then built into the very fiber of mathematics, will just be confounding to us.
- So then, why not stop using it?
- Look, behavioral economics hasn't been invented yet, so I don't have time to explain. It has to do with the fact that once a standard is entrenched enough, even if it's bad, everyone must conform to it because defectors will be seen as having something to hide.
- Ok, but, what ex...
The door swings open and Leibniz pops his head in
- You mentioned in this future there are machines that can do a near-infinite number of computations.
- Yeah, you could say that.
- Was our mathematic not involved in creating those machines? Say, the CLT de Moivre is working on now?
- I guess so, the advent of molecular physics would not have been possible without the normal distributions to model the behavior of various particles.
- So then, if the CLT had not exited, the knowledge of mater needed to construct your computation machines in the first place wouldn't have been, and presumably you wouldn't have been here warning us about the CLT in the first place.
- Hmph.
- You see, the invention of the CLT, whilst bringing with it some evil, is still the best possible turn of events one could hope for, as we are living in the best of all possible worlds.
If you enjoyed this article you might also like:
- Confounding via experimenting
- Truth value as magnitude of predictions
- Neural networks as non-leaky mathematical abstraction
- If Van der Waals was a neural network
Published on: 2020-05-04





{kind=link}